Choose the right modelbefore production
Compare local and API models against real prompts, skills, and expected outputs.
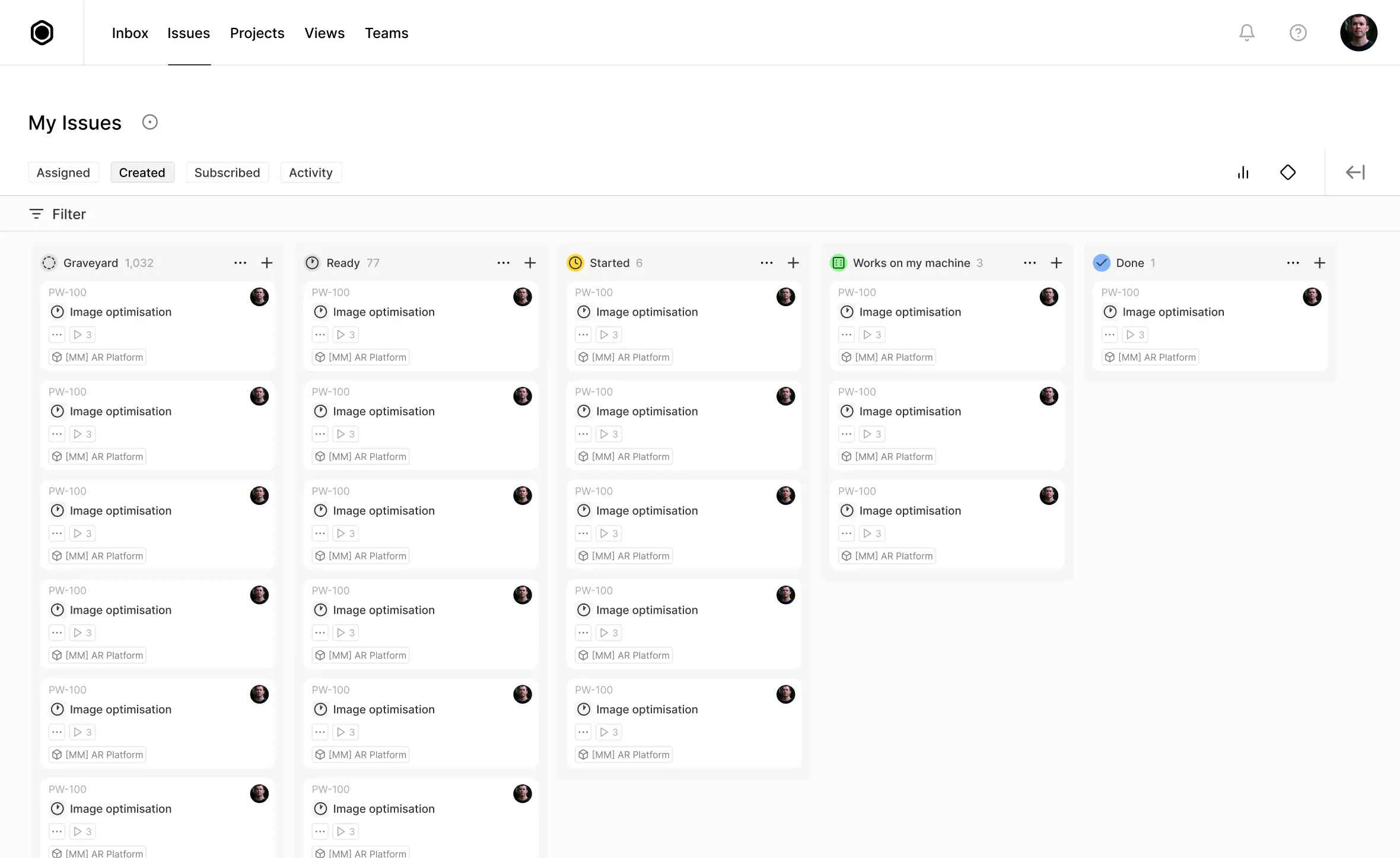
Compare real outputs
Run the same prompt across selected models.
Test local and API models
Evaluate downloaded models next to paid providers.
Score against expectations
Define the target result and find the closest match.
Decide with evidence
Choose based on fit, not guesswork.
Evaluate the models your product depends on.
Compare local and hosted models on the same prompts before you build.
MEASURE TWICE. CUT ONCE.
Built for model decisions
Evalvo gives developers a local-first way to compare candidate models, inspect real outputs, and choose with evidence before production.



Evaluate models before you ship
Prompt and skill setup.
Start from the task your product actually needs to solve.
Local and API model lineup.
Compare models on your machine next to hosted providers.Arena comparisons.
Run the same prompt across selected models and inspect the differences.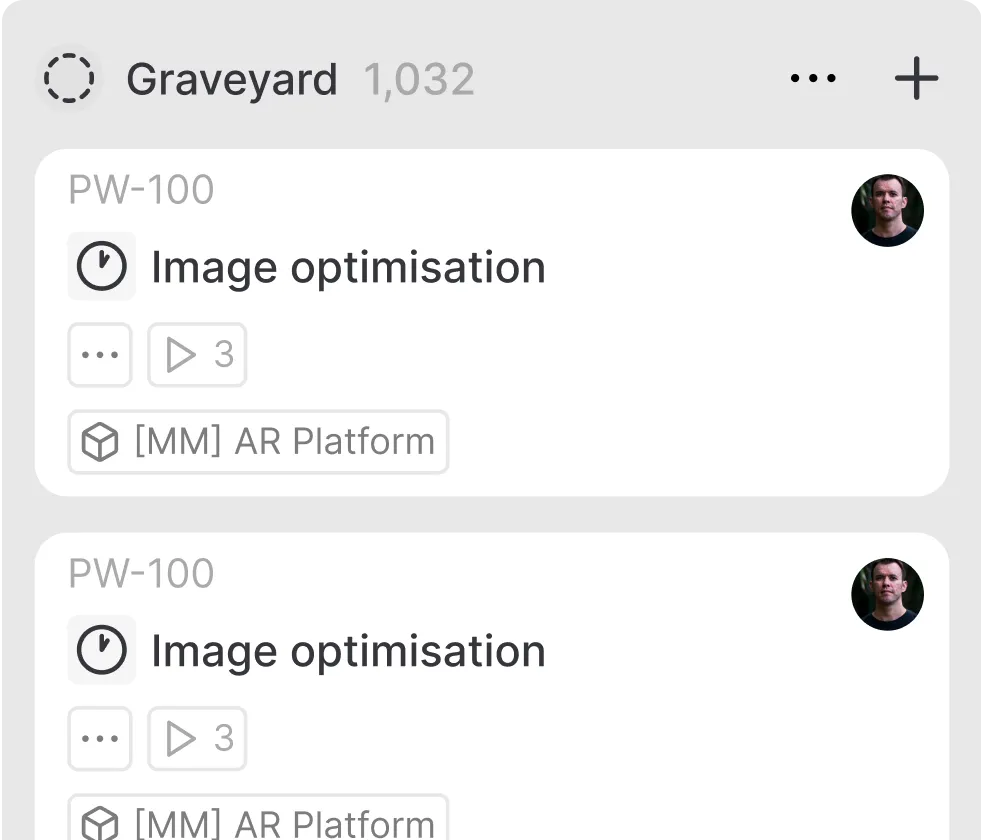
Expected outputs.
Define what a good answer should look like before scoring model fit.
Decision reports.
Use evaluation evidence to decide which model belongs in production.
Built on the open-source AI community
Evalvo brings together the tools developers already use to run local models, compare outputs, and evaluate results with confidence.

Run and manage local models with a developer-friendly runtime.
Ollama
Local model runtime

Access model architectures, tokenizers, and community model workflows.
Hugging Face Transformers
Model library and hub

Serve open models with fast inference when experiments need scale.
vLLM
High-throughput serving

Compare local and paid models through a consistent provider interface.
LiteLLM
Provider routing layer

Efficient local inference for GGUF models across everyday machines.
llama.cpp
Local inference engine

Run repeatable model evaluations with an open-source benchmark harness.
lm-evaluation-harness
Evaluation framework
Pricing
Start self-hosted for local model evaluation. Upgrade when your team needs API model comparisons, fine-tuning workflows, and governance for production decisions.
Free
$0
Self-host Evalvo locally
Compare local models side by side
Run arena prompts on your machine
Basic evaluation reports
Startup
$15 per user/month
Billed annually
Everything in Free, plus...
Compare API and local models
Fine-tuning evaluation workflows
Shared runs and prompt history
Team workspaces
Exportable decision reports
Enterprise
Custom
Everything in Startup, plus...
Private deployment options
Custom model connectors
SSO and admin controls
Audit-ready evaluation exports
Priority support and SLA
Got Questions?
If you can't find what you're looking for, get in touch.